Determining Optimal Core Count with `hyperfine` and `pytest`
Problem
At SEEK, we use buildkite to run pytest from a dockerised ETL pyspark container.
However, with ~1,500 tests and counting, our tests have been taking > 5 minutes and resulting in unfavourable feedback times.
By default, pytest will only use one core to run tests, however with the pytest plugin pytest-xdist, you can utilise as many cores available to run your testing but up to a point:
- Set too low,
pytestwill not fully utilise the parallelism available on the machine. - Set too high,
pytestwill think that there’s more cores than it has available and reflect performance degradation.
As such, for the machines I plan on running on (AWS’ c7g.4xlarge i.e. AWS’ ARM Graviton) machine, I used hyperfine to experiment the most optimal CPU cores
Setup
To set the context, I have a unit testing script that’s run inside a docker container which is invoked by the Makefile, with the number of cores for pytest being passed as an environment variable. Here’s the bash script:
Makefile
.PHONY: test
test:
docker-compose -f cicd/tests/docker-compose-test.yml up --abort-on-container-exit $(service)
cicd/tests/docker-compose-test.yml
version: '3.8'
services:
unit:
image: # ecr image redacted for privacy
entrypoint: /usr/local/app_user/test_pipelines.sh
volumes:
- ../../test_pipelines.sh:/usr/local/app_user/test_pipelines.sh
environment:
- pytest_cores
bash script
#!/usr/bin/env bash
set -eux
echo "Setting up environment"
PYTEST_OPTIONS="--durations=0 --no-cov-on-fail --cov-branch --cov-report term-missing --cov-fail-under=0.00"
pytest_cores=${pytest_cores:-4} # passed in as an env var from docker-compose
echo 'pytest_cores: ' $pytest_cores
echo "Unit Test - All Pipelines"
pytest -n $pytest_cores $PYTEST_OPTIONS src/
Benchmarking with Hyperfine
The primary aim was to find out the optimal number of cores required to make our tests run faster. That’s where hyperfine comes in.
To determine the best core count, I used the following hyperfine command:
hyperfine --runs 3 -P cores 2 10 'make test service=pipelines pytest_cores={cores}' --export-markdown pytest-cores.md
Here’s a breakdown of the command:
--runs 3: Run the command 3 times and take the average.
-P cores 2 10: Vary the number of cores from 2 to 10.
make test service=pipelines pytest_cores={cores}: The command being benchmarked where {cores} is a placeholder that hyperfine replaces based on the current loop.
--export-markdown pytest-cores.md: Export the results into a markdown file for further analysis.
Analysis
Results
| Command | Mean [s] | Min [s] | Max [s] | Relative |
|---|---|---|---|---|
make test service=pipelines pytest_cores=2 | 234.301 ± 4.784 | 230.408 | 239.641 | 1.72 ± 0.05 |
make test service=pipelines pytest_cores=3 | 178.949 ± 2.660 | 177.008 | 181.980 | 1.31 ± 0.03 |
make test service=pipelines pytest_cores=4 | 151.718 ± 3.913 | 149.024 | 156.206 | 1.11 ± 0.04 |
make test service=pipelines pytest_cores=5 | 140.316 ± 3.379 | 138.189 | 144.212 | 1.03 ± 0.03 |
make test service=pipelines pytest_cores=6 | 136.448 ± 2.899 | 133.942 | 139.623 | 1.00 |
make test service=pipelines pytest_cores=7 | 136.451 ± 2.571 | 134.383 | 139.329 | 1.00 ± 0.03 |
make test service=pipelines pytest_cores=8 | 141.022 ± 2.241 | 139.504 | 143.596 | 1.03 ± 0.03 |
make test service=pipelines pytest_cores=9 | 147.063 ± 1.624 | 145.626 | 148.825 | 1.08 ± 0.03 |
make test service=pipelines pytest_cores=10 | 152.674 ± 2.731 | 150.211 | 155.611 | 1.12 ± 0.03 |
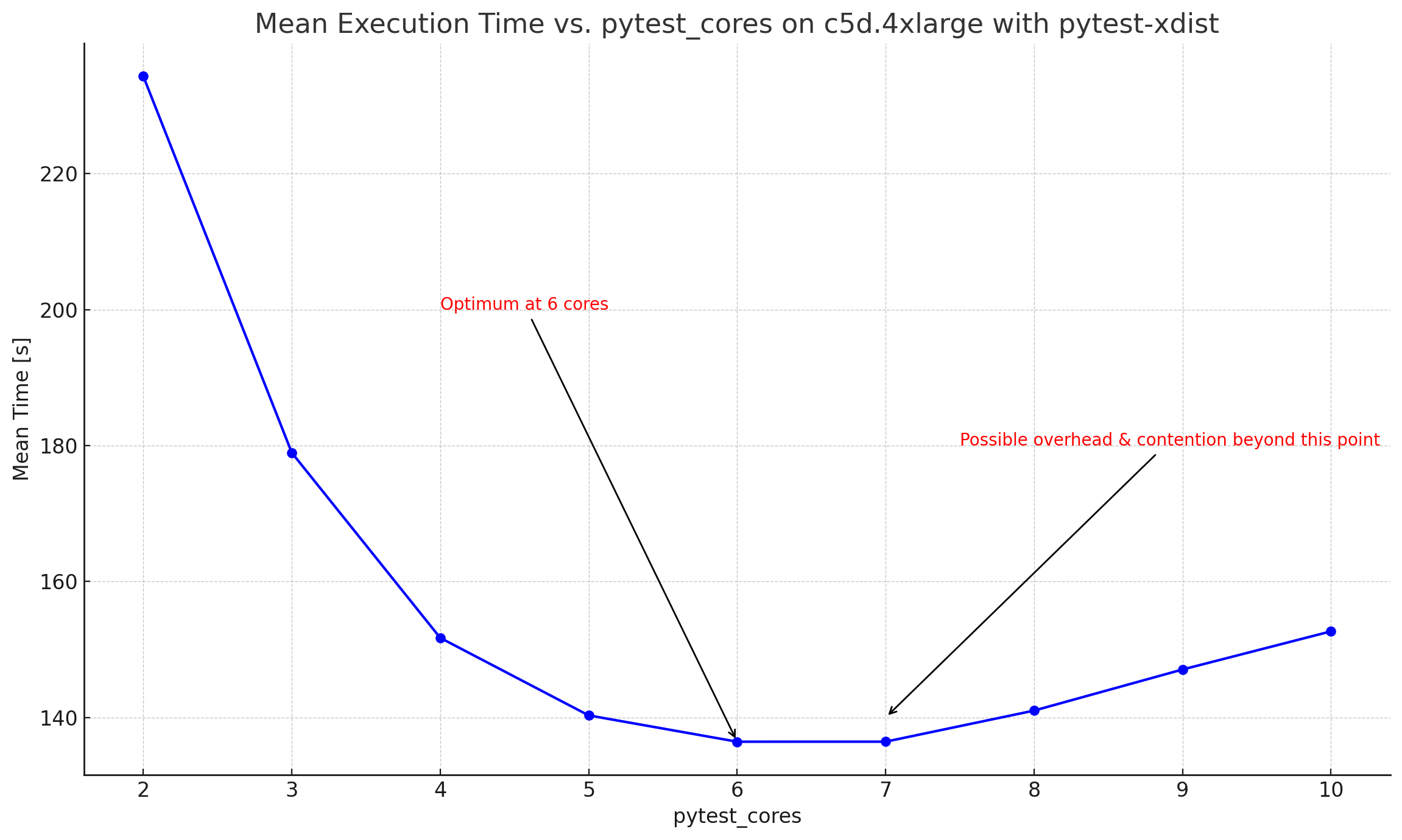
From the data, we can clearly see a general decrease in the mean execution time as the number of cores increases from 2 to 6. However, after 6 cores, there’s an increase in the time it takes for the tests to execute.
It’s essential to recognize that while increasing concurrency (by adding more cores) can speed up execution, it doesn’t always lead to linear improvements. There’s a sweet spot, which in this case is around 6 cores for the c5d.4xlarge instance. Beyond this point, any performance gains from parallel execution are offset by the overheads introduced.
Conclusion
By combining the power of hyperfine and pytest, it became straightforward to determine the optimal number of cores needed for my tests. Not only does this help in reducing test run times, but it also aids in optimising resource utilization.
References
Check out my related postss:
Code used to generate results
# Annotating the graph with context
plt.figure(figsize=(12, 7))
plt.plot(cores, mean_times, marker='o', linestyle='-', color='b')
plt.title("Mean Execution Time vs. pytest_cores on c5d.4xlarge with pytest-xdist")
plt.xlabel("pytest_cores")
plt.ylabel("Mean Time [s]")
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
# Annotations
plt.annotate('Optimum at 6 cores', xy=(6, 136.448), xytext=(4, 200),
arrowprops=dict(facecolor='red', arrowstyle='->'),
color='red')
plt.annotate('Possible overhead & contention beyond this point',
xy=(7, 140), xytext=(7.5, 180),
arrowprops=dict(facecolor='red', arrowstyle='->'),
color='red')
plt.tight_layout()
plt.show()